数据分析系统中实时性的高效资源调度对其性能(吞吐量、作业时间)是至关重要的,本文解决在平台上数据分析应用仅有极少先验知识前提下的高效资源调度。本文算法能够保证相对于最优的基于完全知识的调度有O(1)-competitive的性能,其有效性也在实际系统中得到了验证。
在过去十年中,数据分析系统Hadoop, Spark已被越来越多的机构如Facebook, Microsoft, Yahoo!等用来进行机器学习和网页索引等的基础设施。由于这些应用大多是用来支撑实时性的决策,故需要最大化作业的吞吐量和最小化作业的平均完成时间。
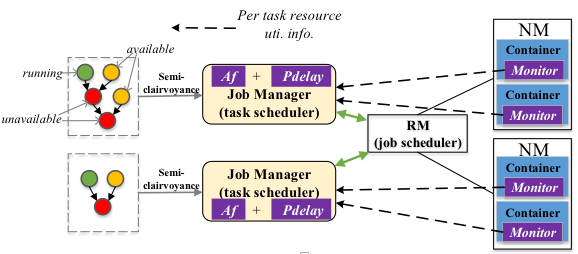
已有的工作大多假设完全的先验的作业特性,包括DAG结构,每个任务的细粒度的资源需求和运行时间。该假设对于重复的作业是成立的,但是对于一般类型的作业难以保证。我们的观察是每个作业中同一阶段(stage)的任务的特性是相似的。基于此,移除了上述强假设,而只依赖于当前可用阶段的任务的特性,而不需要完全的作业结构。一方面,我们证明了,即使是基于部分先验知识,提出的调度算法仍然能够保证相对于最优的基于完全知识的调度有O(1)-competitive的性能(makespan和平均作业完成时间)保证。另一方面,我们将算法实现在了实际系统(Spark on YARN)中,并在28节点的系统中验证了性能提升。
发表论文
- Xiaoda Zhang, Zhuzhong Qian, Sheng Zhang, Xiangbo Li, Xiaoliang Wang and Sanglu Lu. COBRA: Toward Provably Efficient Semi-Clairvoyant Scheduling in Data Analytics Systems. In INFOCOM, 2018. (第一标注)